PPT 10 错误恢复与 ARIES
10. PPT 10 错误恢复:崩溃后,数据库怎样回到正确世界¶
这一章以 第十四章 数据恢复.docx 为主要讲解来源。PPT 给了 ARIES 三阶段,Word 笔记把 WAL、checkpoint、group commit、fuzzy checkpoint、logical undo、LSN、DPT、ATT、CLR 的做题含义讲得更完整。
先抓住恢复系统的目标:
10.1 WAL:先写日志,再改数据库¶
Write-Ahead Logging:
为什么?
日志通常被假设在 stable storage 里:
10.2 Redo 和 Undo:一个负责补做,一个负责撤销¶
Redo:
Undo:
一句话:
winners:
losers:
10.3 日志记录:恢复时不是猜,是顺着日志重放¶
常见日志:
old_value 用来 Undo:
new_value 用来 Redo:
如果 T2 是用户主动 abort:
如果撤销过程中又崩溃,补偿日志能告诉恢复系统:
10.4 checkpoint:不用每次从日志开头重来¶
没有 checkpoint:
日志很长时太慢。
checkpoint 的作用:
传统 checkpoint 大致步骤:
恢复时:
10.5 Force / No-force:commit 时要不要立刻刷数据页¶
force:
好处:
坏处:
no-force:
好处:
坏处:
现代数据库通常偏向 no-force,所以恢复算法要能 redo。
10.6 Group commit:多个 commit 日志攒一起刷¶
如果每个事务 commit 都立刻刷一次日志:
Group commit:
直觉:
它减少刷盘次数,但仍要满足 WAL:
10.7 Fuzzy checkpoint:checkpoint 时不让全世界停下来¶
普通 checkpoint 如果要求事务都停下、脏页都刷完,会很重。
Fuzzy checkpoint:
等这些脏页都安全写出后:
磁盘上会有指针指向:
恢复从那里开始更安全。
10.8 物理 Undo 和逻辑 Undo¶
物理 Undo:
例子:
逻辑 Undo:
为什么需要逻辑 Undo?
Word 笔记的场景是:
如果 T1 abort 时直接把 C 恢复成 T1 前的旧值,可能会抹掉 T2 的合法修改。
所以逻辑 Undo 记录逆操作:
看到这些词要警觉:
它不是普通 old/new value 恢复题。
10.9 ARIES 的一句话:重复历史,再撤销失败者¶
ARIES 的核心口号:
也就是:
三阶段:
不要跳过 Analysis。2025 review 很喜欢直接问 DPT/ATT/CLR。
10.10 LSN、PageLSN、DPT、ATT、CLR¶
这张 Word 图保留,因为 ARIES 的数据结构靠表格更容易对齐。
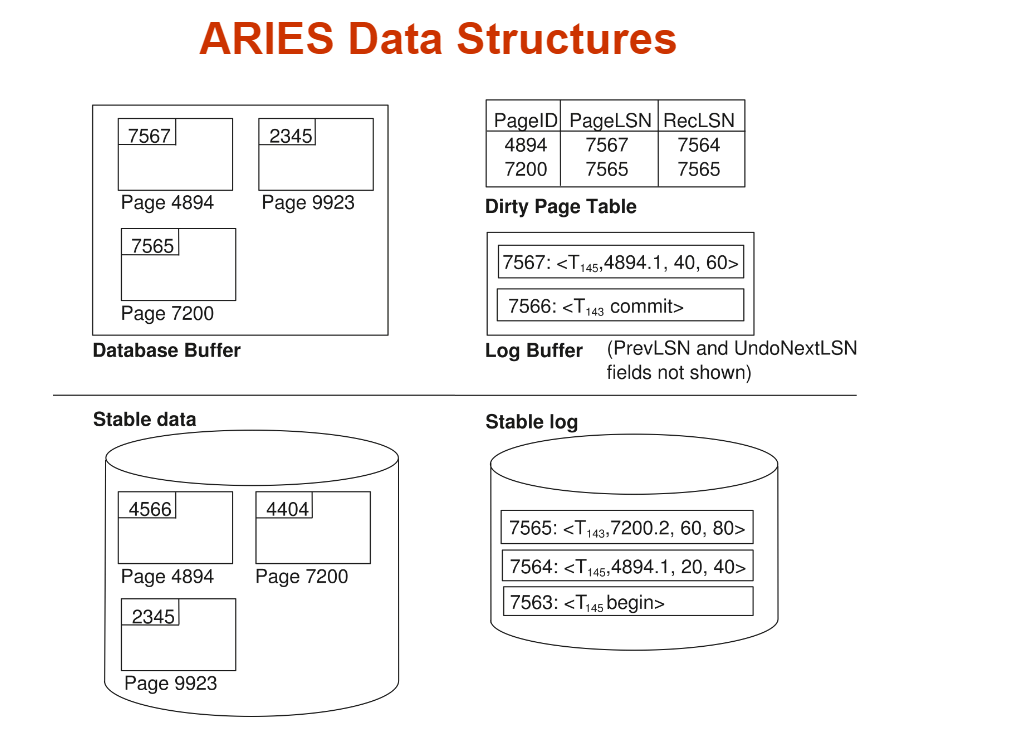
核心术语:
LSN:Log Sequence Number,日志编号,越往后越大。
PageLSN:某个数据页已经反映到哪个 LSN。
ATT:Active Transaction Table,活跃事务表。
DPT:Dirty Page Table,脏页表。
CLR:Compensation Log Record,补偿日志记录。
ATT 里通常记:
DPT 里通常记:
RecLSN 是 Redo 起点的关键。
更准确地说:
人话:
CLR 用来记录 Undo 已经做过的事情:
10.11 Analysis 阶段:从 checkpoint 扫到 crash,重建现场¶
Analysis 从最近 checkpoint 开始,扫描到 crash。
目标:
扫描规则:
遇到事务 update:事务加入/更新 ATT,LastLSN 更新。
遇到某页 update:如果页不在 DPT,加入 DPT,RecLSN 设为这条 update 的 LSN。
遇到 commit:事务状态改为 committing。
遇到 end:事务从 ATT 移除。
扫描结束后:
Redo 起点:
如果题目问:
第一反应:
10.12 Redo 阶段:不是所有日志都真的重做¶
Redo 从:
开始向后扫描到 crash。
ARIES 叫 repeating history,所以 winners 和 losers 的历史都先考虑 redo。
但每条日志是否真的 redo,要检查。
对一条更新页 P 的日志,常见跳过条件:
否则:
这里最容易错的是:
10.13 Undo 阶段:从 loser 的 LastLSN 往回撤¶
Undo 输入:
起点:
ARIES 通常每次选择当前最大的 LSN 往回撤。
撤一条普通 update 时:
撤到事务 start:
如果遇到 CLR:
记忆:
10.14 一道 ARIES 题怎么下手¶
不要直接写答案。按三张表走。
第一步,画日志表:
第二步,Analysis:
第三步,Redo:
第四步,Undo:
考场最常见输出:
10.15 Recovery A4 规则¶
WAL:先写日志,再改数据库页。
Redo winners,Undo losers;ARIES 先 redo history,再 undo losers。
checkpoint 减少恢复扫描长度。
no-force commit 快,但崩溃后可能需要 redo。
group commit 把多个 commit 日志一起刷盘。
fuzzy checkpoint 记录 ATT/DPT,脏页之后慢慢刷。
逻辑 Undo 撤销操作,不是简单恢复 old value。
LSN 是日志编号;PageLSN 是页已反映到的日志编号。
ATT 记录活跃事务和 LastLSN。
DPT 记录脏页和 RecLSN。
Analysis:重建 ATT/DPT,找 losers 和 min RecLSN。
Redo 从 DPT 最小 RecLSN 开始。
Redo 跳过条件:页不在 DPT;LSN < RecLSN;PageLSN >= LSN。
Undo 从 losers 的 LastLSN 往回撤;每撤一条 update 写 CLR。
CLR 不再被 undo,沿 UndoNextLSN 继续。